CI-SpliceAI High Confidence Regions

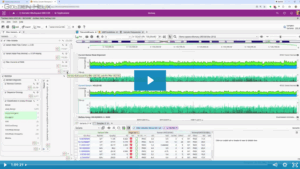
Introducing CI-SpliceAI High Confidence Regions track Last year, we introduced genome-wide precomputed CI-SpliceAI scores for VarSeq, enabling the detection of splice-altering variants outside of canonical splice motifs. These scores make it significantly easier to identify cryptic splice gains, splice losses, and other splicing events that may be missed by traditional…
Read more →