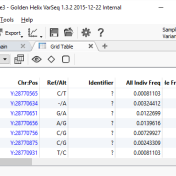
Wednesday, April 6th 12:00 pm EDT As the number of samples and associated data volume in a testing lab increases, it becomes imperative for labs to leverage state of the art warehousing technology that not only organizes data, but also aides and enables researchers and clinicians to perform further analysis, and ongoing research. Built on the algorithms and high-performance storage… Read more »
In 1914, the German cytologist Theodor Boveri coined the phrase “Cancer is a disease of the genome”. At this time, his ideas were as equally revolutionary as they were highly contested. Fast forward. More than a hundred years later, Next-Generation Sequencing effectively permits a highly sensitive analysis of cancer cells. It can help us to understand mutations associated with cancer… Read more »
Thank you to all who submitted an abstract in the 2016 Abstract Challenge, it was a great success! With more than 30 submissions and a wide variety of topics, selecting only 3 winners very difficult! With that being said, here are the top 3 winners for this year’s Abstract Challenge: Our 1st place winner is Dr. Folefac Aminkeng, Postdoctoral Fellow… Read more »
Wednesday, March 2nd 12:00 pm EST Clinical labs must have the ability to go from a collection of samples and associated variants to a professional report documenting a short list of clinically relevant variants. Cancer Gene Panels are a common clinical application for genetic tests. In this webcast we will show how VarSeq and VSReports can be used to go… Read more »
As VarSeq continues its adoption amongst clinical labs and researchers looking for reproducible workflows for variant annotation, filtering and interpretation, we have continued to prioritize the addition of features to assess the quality of the upstream data at a variant, coverage and now sample level. The Importance of Quality Assurance Sample prep and sequencing problems are difficult to detect through the analysis… Read more »
Scaling is in our DNA: Making Genomics Accessible One of the things I absolutely love about the work we do at Golden Helix is keeping up with the changes in data analysis driven by the iterative and generational leaps in technology. But one thing has always been a constant since day one: we break preconceived notions of what scale of… Read more »
Genetic Data Warehousing e-Book In our webcast last week, we announced the upcoming release of VSWarehouse, a scalable genetic data warehouse for VarSeq. Genetic data warehousing becomes more important as Next-Generation Sequencing is taking off in the clinic, creating significant data management issues for clinicians, scientists and IT professionals alike. How can we retain the massive amounts of data coming out… Read more »
New SVS Meta-Analysis Example Project The latest version of the GWAS E-book featured a chapter on Meta-Analysis. We are pleased to make the project used in this chapter available as an example project for SVS (SNP & Variation Suite). This blog post will walk you through the analysis steps used in the example project. This information is also contained in… Read more »
Yesterday, it was my pleasure to share in a live webcast our integrated solution for genetic data warehousing, VSWarehouse. Although we had a great set of questions at the end of our presentation, we didn’t have time to answer all of them, so here is a selection of the remaining representative questions and my answers. We can provide a hosted version… Read more »
Compound Heterozygous Workflows: Including a 2nd Affected Child Looking for Compound Heterozygous regions for a trio is fairly straight forward in VarSeq, we include this workflow in our shipped Exome Trio Template. An example of which is included with our Example Projects which can be found by going to File > Example Projects > Example YRI Exome Trio Analysis. But… Read more »
With the release of our updated GWAS E-book, we have recently updated the GWAS example project (SNP Genome-Wide Association Tutorial – Complete). This updated project includes more details about how spreadsheets were generated, how to generate plots and which images were used for the GWAS E-book. This information can be found in the User Notes view in the project navigator and… Read more »
So, why are we launching a new data warehouse product? Why did we build VSWarehouse? According to Grand View Market Research, the next generation sequencing (NGS) market size was $2.0 billion (USD) globally in 2014. This number is expected to grow from 2015 to 2022 at an annual rate of about 40%. What drives this phenomenon is the increasing number… Read more »
I hope your 2016 is off to a good start! We at Golden Helix have been busy preparing and planning new and updated content for the community. First up is an updated GWAS ebook which includes a sample Meta-analysis example project. In the 2nd edition, we start with an introduction to GWAS exploring its biology and origins as well as… Read more »
There is no doubt that we have big data in the field of genomics in general and Next Generation Sequencing specifically. Illumina’s latest HiSeq X can produce 16 genomes per run, resulting in terabytes of raw data to crunch through. Yet all that crunching is not the hard part. So, what is the main obstacle to scientists being able to… Read more »
The holiday season has come to a close and we are headed to sunny San Diego for PAG XXIV! This year, our President and CEO Andreas Scherer along with Greta Linse Peterson our Director of Services and Mary Makris our Operations and Marketing Manger, will be manning the Golden Helix booth, so stop by booth 129 to say “Hi!”. Since PAG XXIII,… Read more »
Golden Helix in 2016 We had a terrific year 2015. It was the year in which we got serious about the clinical testing market. We successfully continued on the path of attracting more referenceable clients such as University of Iowa, Baby Genes, Prevention Genetics and many more. We rounded out our VarSeq suite by adding more clinically relevant features and… Read more »
The most common use of the VarSeq Match Gene List algorithm of course is to determine if the variants in your data set are contained within your genes of interest. As an example of this, say you are working with a whole exome trio and only want to consider those variants that are contained within the 56 genes recommended by… Read more »
We have just released SVS version 8.4.2, and included in the release is a new script for visualizing Meta-Analysis results with a Forest Plot. You can find full details on all the new and updated features included with the update in our Release Notes. Release Notes from all our software products can be found on our Support Bulletin web page… Read more »
Probably one our most popular public annotation sources we curate and update is the database of Non-Synonymous Functional Predictions (dbNSFP). In it’s recent update, it has expanded the predictions to include FATHMM-MKL and VarSeq now incorporates this new prediction into its voting algorithm of now 6 different discrete predictions per variant. You can update to dbNSFP 3.0 using the built-in… Read more »
As VarSeq’s adoption has grown among analysts using whole exome data to diagnose rare diseases, a couple of family designs outside of the common trio of an affected child and both parents have come up frequently. While having both parents provides the maximum power to discover de novo mutations and recessively inherited variants, it is not always possible to contact… Read more »