The most common use of the VarSeq Match Gene List algorithm of course is to determine if the variants in your data set are contained within your genes of interest. As an example of this, say you are working with a whole exome trio and only want to consider those variants that are contained within the 56 genes recommended by ACMG for further analysis. To do this you will first annotate your data by a gene annotation sources for example RefSeq Genes 105v2, NCBI using the Add > Annotation option in your VarSeq project.
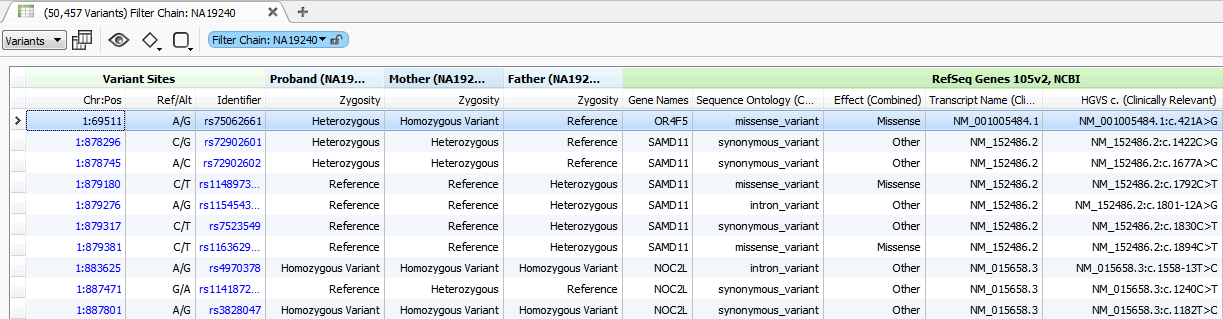
Fig.1. Imported variants from YRI Trio are annotated against RefSeq Genes
Once the annotation is present go to Add > Computed Data… and then under the Annotate selection select the Match Gene List algorithm. You will then be prompted to select the source and the column from the source that will be use to match to your list. In this example we will pick the first RefSeq group of columns and the associated Gene Names field.
Now enter in the list of 56 genes from the ACMG recommended list, give the new field an informative name, and click OK.
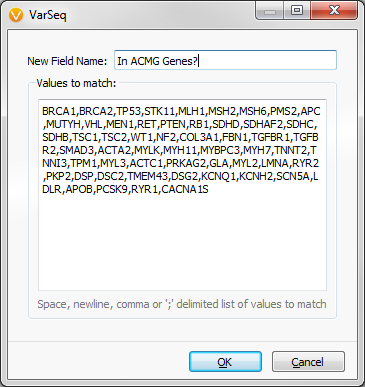
Fig.2. List of ACMG recommened genes
The result of the algorithm will be a column that can then be used to filter your data to only those variants of interest.
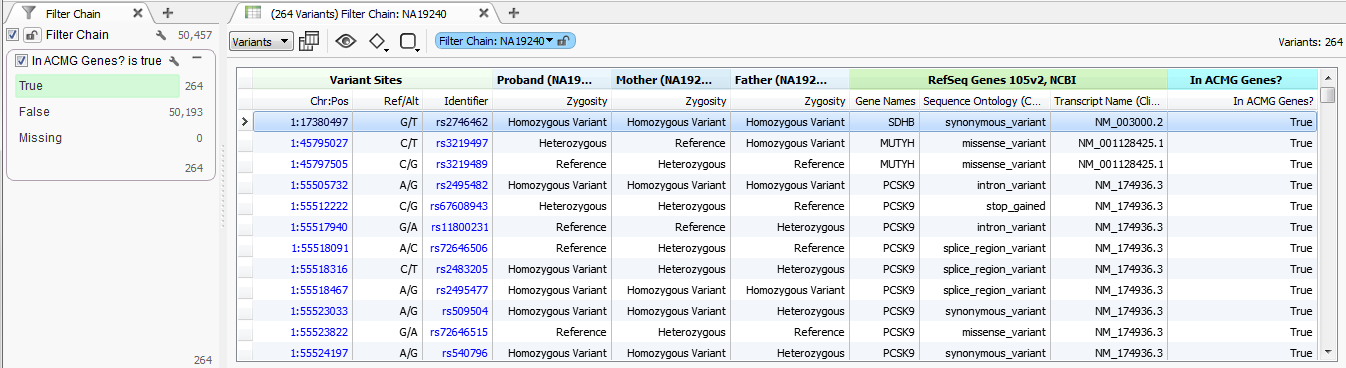
Fig.3. Filter card for the Match Gene List algorithm
This algorithm can also be used to match any string field with a list of string entries. For example, what if you had a list of OMIM Disorder IDs for disorders associated with Cardiomyopathy and wanted to see which variants in your data were associated with these disorders? The Match Gene List algorithm can be used.
Similar to gene matching, the first step is to annotate your data by the source that contains the information to be matched. For this situation the OMIM Disorder IDs can be found in the OMIM Genes 2015-12-01, GHI annotation source, which you can once again access by going to Add > Annotation and selecting the track from the Secure Annotations location.
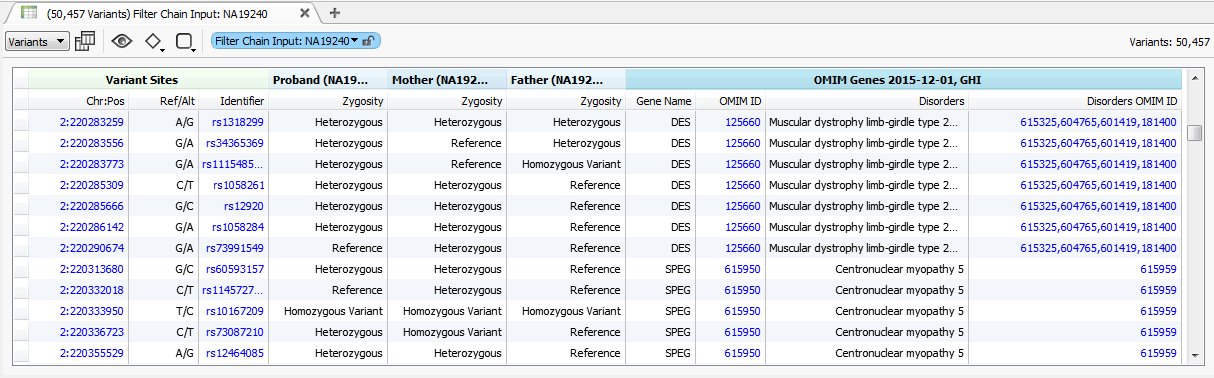
Fig.4. Variants annotated by OMIM Genes source
Launch the Match Gene List algorithm, but this time select the OMIM Genes column groups and the associated Disorders OMIM ID column. Then enter in your list of OMIM Disorder IDs associated with Cardiomyopathy disorders to complete the process.
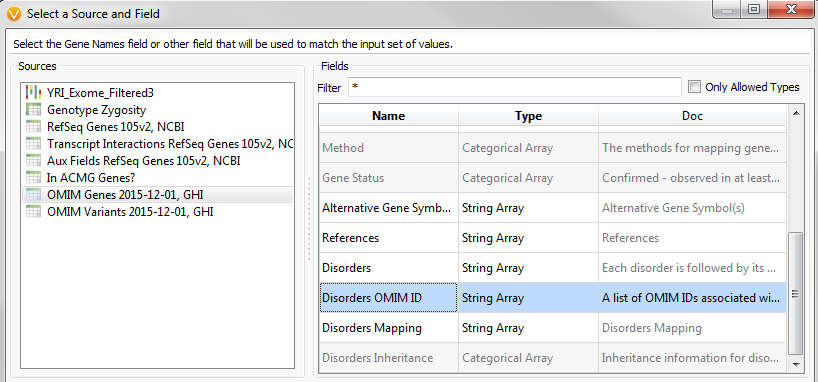
Fig.5. Source selection dialog for OMIM Disorder ID matching
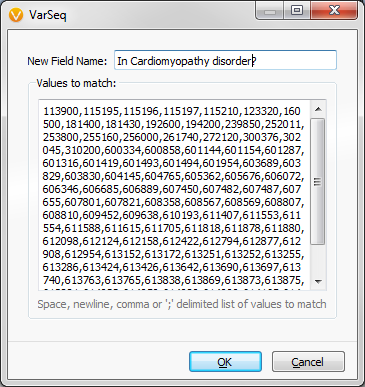
Fig.6. Cardiomyopathy disorder IDs from OMIM annotations
The result is a column that can be used to filter your data down to your variants of interest.
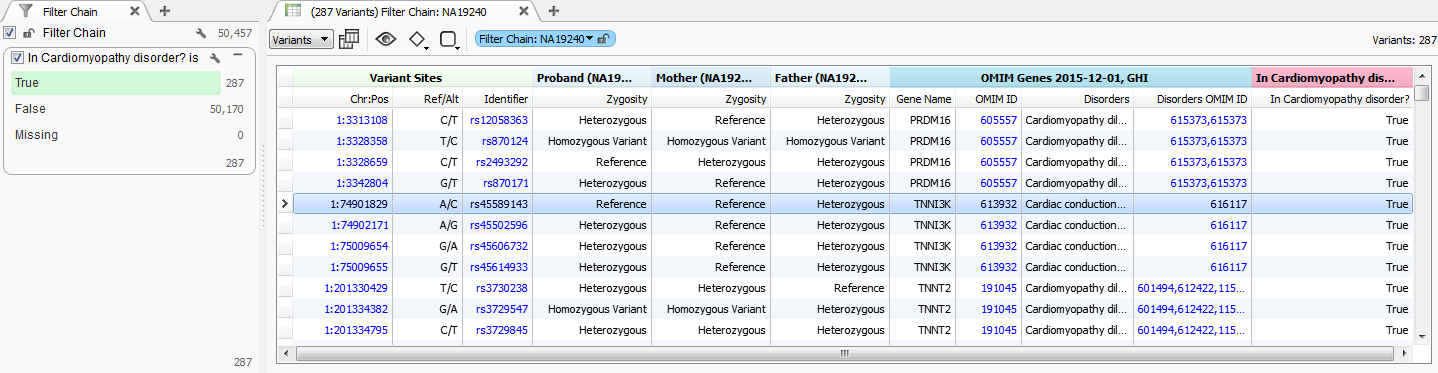
Fig.7. Filtered dataset for associated Cardiomyopathy disorders
Coming in the next release of VarSeq (version 1.3.2) is an additional Match Gene List algorithm that can accept a different list for each sample in your dataset and then performs sample specific annotations based on the source selected. So keep an eye out for this new feature!
If you have any questions, please contact [email protected].