Over the last decade, DNA sequencing has made vast technological improvements. With the cost of sequencing decreasing significantly, sequencing technology has become a product for the masses. The sequencing technology and programs that were once used exclusively by major research institutions are now becoming available in many research facilities around the globe. These tools produce large amounts of data sets that require specialized processing before meaningful interpretation can begin.
The handling and interpretation of sequencing data from the current generation of sequencing instruments has fallen to the field of bioinformatics. Trained bioinformaticians are in short supply (Wellesen, 2014). Some larger laboratories have bioinformaticians on staff to support the sequencing efforts of the lab. Many smaller laboratories aren’t able to support their own bioinformatician, and must chose to (1) use a shared resource or “bioinformatics core” at their host institution, (2) outsource the analysis, or (3) learn to do the analysis with existing resources (MacLean & Kamoun, 2012).
In other words, the field of genomic research is being plagued with a massive wave of data waiting to be analyzed while there is a shortage of experts to conduct this kind of work.
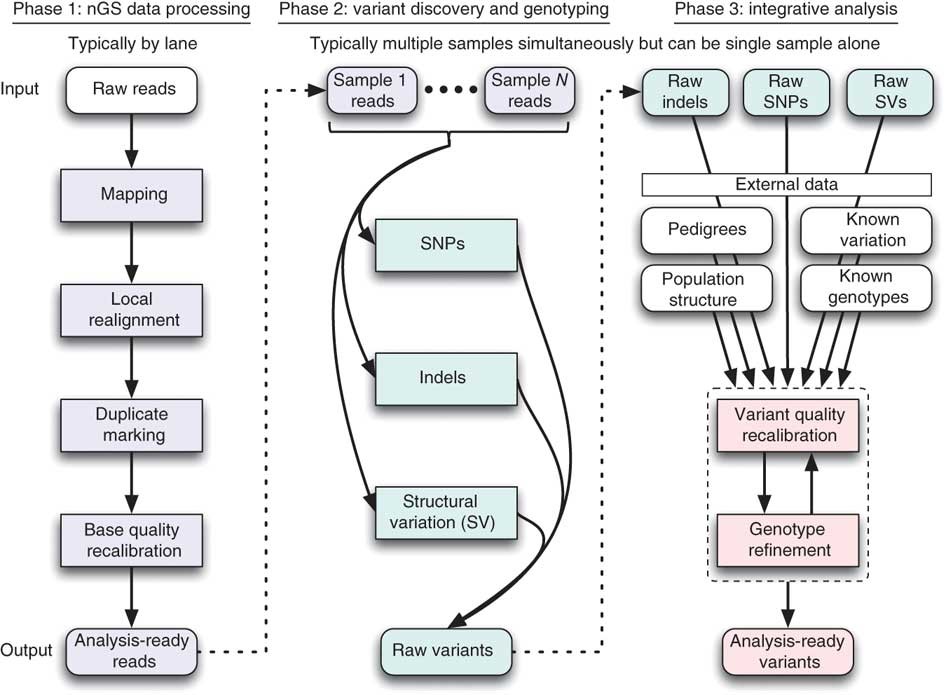
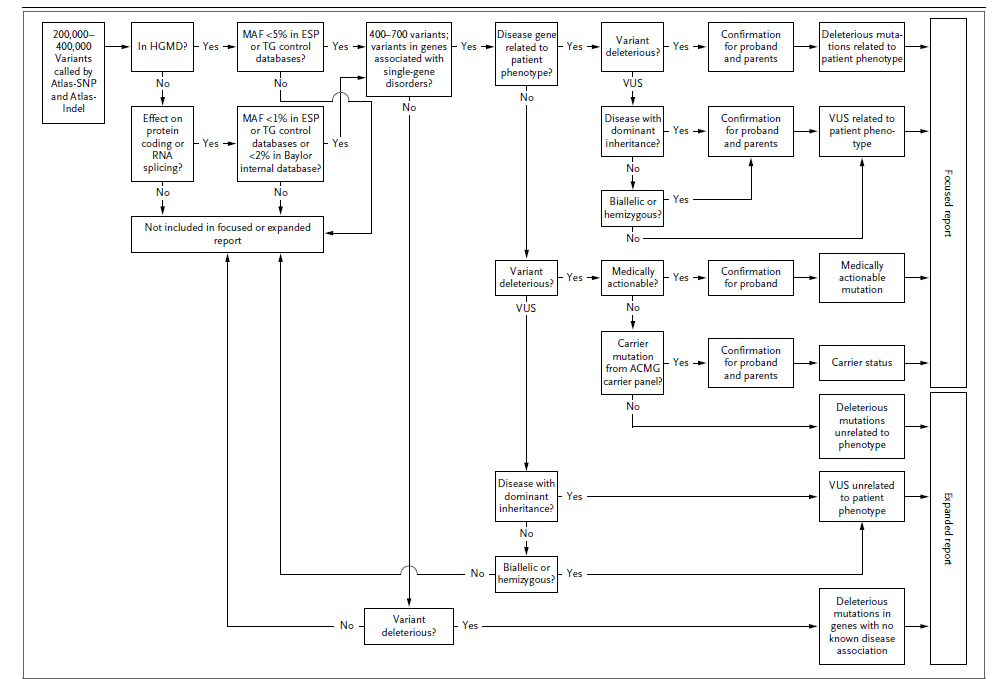
Figures 1 and 2 show the complexity of common NGS workflows. These figures show the difficulty that a researcher faces on a daily basis. It is important for clinicians, life scientists, and environmental researchers to use and gain familiarity with bioinformatics resources, as well as understand the underlying theoretics and principals of the concept. For correct interpretation with minimal error or discrepancy in results, researchers must understand the mechanics of this process. Clinicians, life scientists, and environmental researchers will become further empowered in their analyses if they are provided with bioinformatics tools. Because of these difficulties, currently progressing their research has proven to be a challenge across the globe.
SVS incorporates a unique graphical user interface that exposes the user to each step in the analysis workflow; a tactile environment that may be especially conducive to learning, yet powerful and flexible enough to perform almost any tertiary analysis workflow. In addition, we see that the usage of SVS has increased for teaching purposes. It not only reduces the need for power users to implement their own code, but also lowers the hurdle for new scientists entering the field to conduct meaningful research.
Baker, M. (2011). Sorting out sequencing data. Nature Methods, 8, 799-803. PMID: 21959132
Escobar, H. (2010). Brief survey report: current trends on NGS data management and analysis. Journal of Biomedical Techniques, 21 (3 Suppl), S12. PMCID: PMC2918157.
MacLean, D., Kamoun, S. (2012). Big data in small places. Nature Biotechnology. 30, 33-34. PMID: 22231089
Wellesen, K. (2014, July 21). Data analysis – still a bottleneck. [Web log]. Retrieved from http://ngs-expert.com/2014/07/21/data-analysis-still-a-bottleneck/



